С увеличением частоты процессора, все более жесткие требования предъявляются к временным характеристикам памяти. В запоминающем устройстве,работавшем с процессором 80386 (16 МГц), время выборки данных соответствовало двум циклам процессора, т.е. составляло 2 х 62,5 нс. = 125 нс. Это означало, что для работы без периодов ожиданий достаточно было иметь запоминающее устройство с временем выборки 100 или даже 120 нс. Однако каждый раз, когда процессор осуществлял выборку данных из динамического запоминающего устройства требовалась перезапись содержимого памяти до того, как ее снова можно будет использовать. Для большинства динамических запоминающих устройств время перезаписи лишь немного меньше, чем время выборки. Кроме того, в динамических запоминающих устройствах требуется периодическая регенерация хранимой в памяти информации. На регенерацию уходит время, составляющее в среднем 6-12% от времени выборки. С учетом указанных обстоятельств фактическое быстродействие динамических запоминающих устройств определялось как время выборки 100 нс. + время перезаписи 90 нс. + дополнительное время на регенерацию. В сумме это составляло более 200нс. А это означает, что в персональных компьютерах даже на базе микропроцессора 80386 с временем цикла 125 нс. применение динамического запоминающего устройства с временем выборки 100 нс. не позволяло обеспечить работу процессора с памятью без периодов ожиданий. Современные схемы динамической памяти имеют время выборки порядка 5 - 10 нсек., но по прежнему не могут обеспечить работу процессора без периодов ожидания, так как тактовая частота процессоров уже превышает 4 ГГц (длительность такта менее 0,25нсек.). Повышение быстродействия памяти достигается сегодня благодаря совершенствованию технологий и схемных решений. Обеспечение необходимого быстродействия системы процессор - память становится все более важным.
Существует несколько способов повышения быстродействия системы процессор - память:
1. Расположить последовательные ячейки памяти в разных банках памяти;
2. Реализовать метод страничной выборки, который заключается в том, что при обращении к памяти задается адрес страницы (строки), а не отдельной ячейки памяти;
3. Организовать синхронную работу памяти и процессора за счет использования внутренней конвейерной архитектуры;
4. Включить в строку динамической памяти встроенный статический КЭШ;
5. Увеличить ширину шины;
6. Повысить тактовую частоту шины и увеличить время в тактах, в течение которого данные доступны для чтения.
При использовании первого метода уменьшение времени обращения к памяти достигается при помощи метода interleaving (чередование), суть которого заключается в том, что в подсистеме памяти организуется последовательное обращение к разным банкам памяти.
В системных платах для 386 и 486 процессоров использовался контроль четности. Для выявления одиночной ошибки количество единиц в каждом байте дополнялось до четного значения. Поэтому модули памяти выпускались с дополнительным разрядом шины данных, отведенным для контроля четности. В типичных настольных персональных компьютерах контроль четности оказался избыточным и производители микросхем отказались от такого контроля.
Модули DIMM допускают работу с современными процессорами при установке даже нечетного числа модулей, т.к. каждый DIMM модуль может включать в себя несколько банков памяти. В простейшей модели динамического ОЗУ имеются два банка: в одном банке размещены все байты с четными адресами, в другом с нечетными. Периодов ожидания не будет, если процессор выполняет команды, извлекаемые из последовательных адресов памяти. Если программа становится непоследовательной, такая ситуация возникает, например, когда имеют место условные или безусловные переходы, вероятность готовности банка к работе становится равной 50%. При последовательном переборе адресов, когда схема управления памятью находится в режиме ожидания данных, считываемых по следующему адресу памяти из первого банка, она устанавливает адрес данных во втором банке. Следующий адрес может считываться немедленно без периода ожидания. Если микропроцессор считывает 10 последовательных участков памяти, требуется один период ожидания только для первого считывания. В результате, среднее число периодов ожидания на весь цикл считывания будет равно 0,1. Подобная архитектура памяти обеспечивает работу динамического ОЗУ с быстродействующими процессорами, но при этом усложняется устройство управления памятью, что связано с необходимостью организации работы банков. Традиционный разрыв между скоростью работы памяти и процессора сокращается за счет внедрения новых технологий производства СБИС памяти.
Долгое время наиболее распространенной была память, работающая в режиме быстрого страничного обмена (Fast Page Mode, или FPM DRAM). Эта память отличается тем, что после выбора строки удерживается сигнал RAS и допускается многократная установка адреса столбца по сигналу CAS, что позволяет организовать блочную передачу данных всей строки матрицы памяти, называемой страницей обмена. Из предыдущего описания работы элемента и микросхемы памяти мы знаем, что столбцы и строки матрицы памяти адресуются при помощи единых адресных линий. В случае квадратной матрицы количество адресных линий сокращается вдвое, но и выбор конкретной ячейки памяти отнимает вдвое больше тактов, ведь номера столбца и строки приходится передавать последовательно. Причем, возникает неоднозначность, что именно в данный момент находится на адресной линии: номер строки или номер столбца? Решение этой проблемы потребовало двух дополнительных выводов, сигнализирующих о наличии столбца или строки на адресных линиях RAS и CAS.
Контроллер преобразует физический адрес ячейки памяти в номер строки и номер столбца, а затем посылает первый из них на адресные линии. Дождавшись, когда адресные сигналы стабилизируются, контроллер устанавливает низкий уровень на линии RAS, сообщая микросхеме памяти о наличии информации на линии. Микросхема считывает этот адрес и подает на соответствующую строку матрицы электрический сигнал. Все транзисторы, подключенные к этой строке, открываются и напряжения с конденсаторов подаются на входы чувствительных усилителей. Чувствительный усилитель строки сохраняет полученную информацию в специальном буфере. Когда микросхема завершает чтение строки в буфер и вновь готова к приему информации, контроллер подает на адресные линии номер колонки и, дав сигналам адреса колонки стабилизироваться, устанавливает на линии CAS низкий уровень. Устройство управления микросхемы памяти преобразует номер колонки в смещение ячейки внутри буфера. Остается установить уже подготовленные данные на линиях шины данных. Это занимает еще какое-то время, в течение которого контроллер ждет запрошенную информацию. На финальной стадии цикла обмена контроллер считывает состояние линий данных, cнимает сигналы RAS и CAS, устанавливая высокий потенциал, а микросхема становится недоступной на время восстановительной перезаписи строки и необходимую регенерацию.
Задержка между подачей номера строки и номера столбца называется "RAS to CAS delay" ( tRCD). Задержка между подачей номера столбца и получением содержимого ячейки на выходе "CAS delay" ( tCAC), а задержка между чтением последней ячейки и подачей номера новой строки "RAS precharge" (tRP).
Рассмотрим работу микросхемы памяти при чтении/записи одного слова (рис.1). На шине адреса контроллер памяти установил адрес строки, затем сигнал RAS, по перепаду адрес принят микросхемой памяти и контроллер памяти устанавливает адрес столбца на шине адреса, затем сигнал CAS, по которому адрес столбца будет принят микросхемой памяти. В результате будет получен доступ к ячейке памяти, которая находится на пересечении строки и столбца. По сигналу WR/RD данные будут прочитаны, или записаны в ячейку памяти. На установку и прием каждого адреса необходимо 3 такта системной шины. Поэтому доступ к данным возможен только после 6 тактов системной шины.
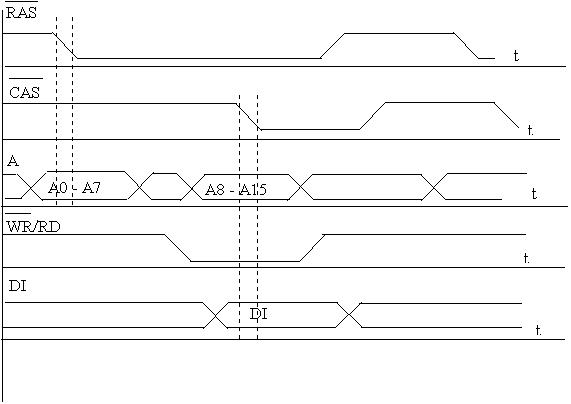
Рис.1. Временная диаграмма режима записичтения одного слова
(при чтении на линии WRRD высокий потенциал).
Страничное чтение производится при активизации строки за счет удержания сигнала RAS. Строка остается активной на все время чтения страницы памяти ( четырех последовательно расположенных слов), что увеличивает скорость чтения из памяти. Например цикл чтения в пакетном режиме четырех ячеек памяти типа FPM может выполняться с затратой шести тактов (установка и дешифрация адреса строки, установка и дешифрация адреса столбца) на чтение первого слова и трех тактов на каждое из следующих трех слов. (рис.2).
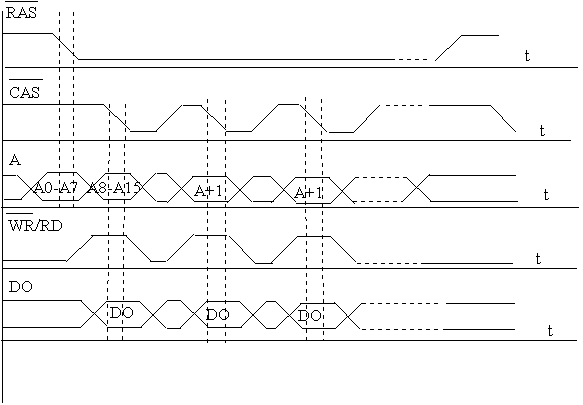
Рис. 2. Временные диаграммы страничного режима записи (чтения).
При работе с обычной DRAM (рис.1) после считывания данных сигнал RAS деактивируется, подготавливая микросхему к новому циклу обмена. В памяти FPM-DRAM контроллер удерживает сигнал RAS в низком состоянии, избавляясь от повторной пересылки номера строки. Строб (импульс) CAS сопровождает установку каждого слова строки (выбор столбца). При последовательном чтении ячеек памяти время доступа сокращается т.к. обрабатываемая строка находится во внутреннем буфере микросхемы, и обращаться к матрице памяти нет необходимости.
Если последовательно поступают запросы запросы на чтение данных из ячеек, принадлежащих разным страницам, то страничная память не дает выигрыша и работа FPM-DRAM происходит в режиме обычной DRAM. Если очередная запрашиваемая ячейка лежит вне текущей (так называемой, открытой) строки, контроллер вынужден деактивировать RAS, выдержать паузу RAS precharge на регенерацию микросхемы, передать номер строки, выдержать паузу RAS to CAS delay и лишь затем приступить к передаче номера столбца.
Ситуация, когда запрашиваемая ячейка находится в открытой строке, называется "попаданием на страницу" (Page Hit), в противном случае говорят, что произошел промах (Page Miss).
Непостоянство времени доступа затрудняет измерение производительности микросхем памяти и сравнение их скоростных показателей друг с другом. В худшем случае время обращения к ячейке памяти (Tобр) составляет:
Tобр= (RAS to CAS Delay + CAS Delay + RAS precharge) нс.
В лучшем случае, если строка активна:
Tобр= CAS Delay нс.
Если память готова к обращению и не требует регенерации:
Tобр= ( RAS to CAS Delay + CAS Delay) нс.
Таким образом, оценка производительность микросхемы требует для своего выражения как минимум трех чисел. Производители микросхем обычно приводят только два значения - время полного доступа (RAS to CAS Delay + CAS Delay); и время рабочего цикла, время доступа к ячейке открытой строки (CAS Delay). Время, необходимое для регенерации микросхемы (RAS precharge), из полного времени доступа обычно исключено. Оно указывается лишь в технической документации, где приводятся все временные значения.
К середине девяностых годов, когда широко использовалась FPM DRAM среднее значение RAS to CAS Delay составляло порядка 30 нс., CAS Delay - 40 нс., а RAS precharge - менее 30 нс. При частоте системной шины в 60 МГц (1такт ~17 нс.) когда на открытие и доступ к первой ячейке страницы уходило около 6 тактов, а на доступ к остальным ячейкам открытой страницы - около 3 тактов была введена схематическая запись, получившая название формулы памяти 6-3-x-x. На первом месте этой формулы записывается время обращения к микросхеме памяти ( RAS to CAS Delay + CAS Delay) выраженное в тактах системной шины, три последующих значения - время цикла CAS Delay, так же выраженное в тактах системной шины.
Повышение быстродействия памяти достигается сегодня благодаря совершенствованию схемных решений. Разрыв между скоростью работы памяти и процессора сократился за счет внедрения новых технологий производства СБИС памяти о которых мы поговорим далее.
Конечно, для полного рассмотрения вопроса 'Динамическая память FPM DRAM (Fast Page Mode ), временные диаграммы страничного чте6ния и записи', приведенной информации не достаточно, однако чтобы понять основы, её должно хватить. Если вы изучаете эту тему, с целью выполнения задания заданного преподавателем, вы можете обратится за консультацией в нашу компанию. В нашей команде работает большой состав специалистов, которые разбираются в изучаемом вами вопросе на экспертном уровне.






